
目录
前言
二次指数平滑法(Holt’s linear trend method)
1.定义
2.公式
二次指数平滑值:
二次指数平滑数学模型:
3.案例实现
三次指数平滑法(Holt-Winters’ seasonal method)
1.定义
2.公式
3.案例实现
加权系数a的猿创选择
点关注,防走丢,征文之次指数如有纰漏之处,时间算法数平实现请留言指教,序列详解非常感谢
参阅
前言
好久没来更时间序列分析算法了,分析法和今天把平滑法这一个常用且宽泛的平滑时序算法给补完。这篇文章完结了就代表整个传统时序预测算法讲完了。滑法文章内容是代码紧接着上篇文章:
一文速学-时间序列分析算法之指数平滑法详解+Python代码实现_fanstuck的博客-CSDN博客_指数平滑法python

下篇文章就是详解单变量时间序列预测的所有模型和算法了。此系列将会一直写到现在比较火热的猿创LSTM短时时序预测以及更多先进且方便的时序预测算法。
希望读者看完能够在评论区提出错误或者看法,征文之次指数博主会长期维护博客做及时更新。时间算法数平实现
二次指数平滑法(Holt’s linear trend method)
从我们之前学过的序列详解简单移动平均法和在此基础之上衍生出来的二次移动平均法(又称趋势移动平均法),一次指数平滑法和二次指数平滑法二者关系与之类似,分析法和可以说原理都一样。平滑
1.定义
在一次指数平滑法的滑法基础之上再去做趋势移动。当时间序列的变动出现直线趋势时,用一次指数平滑法来进行预测仍将存在着明显的滞后偏差。修正的方法也是在一次指数平滑的基础上再进行二次指数平滑,利用滞后偏差的规律找出曲线的发展方向和发展趋势,然后建立直线趋势预测模型,故称为二次指数平滑法。
2.公式
我们再来看看一次指数平滑法的公式:
设时间序列为为加权系数,
,一次指数平滑公式为:
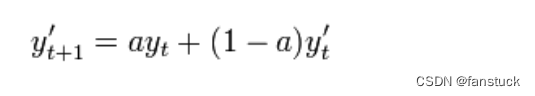
![]()
为t+1时刻的预测值,即t时刻的平滑值
,
为t时刻的实际值;
为
时刻的预测值,即为上一时刻的平滑值
.很明显该公式是由移动平均公式改进而来。
我们和二次移动平均法一样如法炮制计算。
二次指数平滑值:
![]()
公式中:
:第t周期的二次指数平滑值
:第t周期的一次指数平滑值
:第t-1周期的二次指数平滑值
:加权系数(平滑系数)
很容易看出二次指数平滑法是对一次指数平滑值再一次指数平滑的方法。所以说还得使用一次指数平滑法之后再作计算。
二次指数平滑数学模型:

3.案例实现
这里我们不再使用上次化学实验的案例1,换个一个案例:
以我国 1965~1985 年的发电总量资料为例,试用二次指数平滑法预 测 1986 年和 1987 年的发电总量:

那么我们只需要读入数据再将我们之前写的SES一次平滑指数法引入就好了:
import pandas as pdimport numpy as npimport Ipynb_importerimport SESdf=pd.read_excel('try_test2.xlsx')首先我们获取一次平滑值,平滑系数还是为0.3:
df=pd.read_excel('try_test2.xlsx')x=df['t']y=df['发电总量y']y_1=SES(y,1,0.3)y_1 
我们获取二次平滑值只需要将一次平滑值再次代入就可以得到:
y_2=SES(y_2,1,0.3)y_2 
那么如果我们要预测t为21时刻的值时,我们需要得到a和b两个参数的值:
#我们需要传入一次平滑预测值和二次平滑预测值,以及t值、平滑系数a和给予的Tdef SES_quadratic(y_1,y_2,s,t,T): a=2*y_1[t-1]-y_2[t-1] b=(s/(1-s))*(y_1[t-1]-y_2[t-1]) y=a+b*T return ySES_quadratic(y_1,y_2,0.3,21,1)这样我们就得到了 t为22时刻的预测值:
![]()

三次指数平滑法(Holt-Winters’ seasonal method)
1.定义
一次指数平滑法针对没有趋势和季节性的序列,二次指数平滑法针对有趋势但是没有季节特性的时间序列,三次指数平滑法则可以预测具有趋势和季节性的时间序列。术语“Holt-Winter”指的是三次指数平滑。该方法分为预测方程和三个平滑方程,一个是水平,一个是趋势,一个是季节性成分,采用平滑参数和,用代表季节性周期,例如一年中季节的数量,季的数量,月的数量。
直接我们在将时间序列数据的时候谈到,时间序列有一下四个时序特性:
- 长期趋势(Trend)
- 季节变化(Season)
- 循环波动(Cyclic)
- 不规则波动(Irregular)
其中季节变化也正是三次指数平滑法所代表的平滑。下面网址就是全述季节性预测算法:
7.3 Holt-Winters’ seasonal method | Forecasting: Principles and Practice (2nd ed)
之前我在第一篇文章也说过:
四种影响因素通常有两种组合方式:
一种是加法模型:Y=T+S+C+I,认为数据的发展趋势是4种影响因素相互叠加的结果
一种是乘法模型:Y=T*S*C*I,认为数据的发展趋势是4种因素相互综合的结果
该方法有两种变体,根据季节性成分的性质不同而不同。当季节变化在整个系列中大致恒定时,优选加法模型,而当季节变化与系列水平成比例时,优选乘法模型。使用相加法,季节性分量在观测序列的尺度中以绝对值表示,在水平方程中,通过减去季节性分量对序列进行季节性调整。在每年内,季节性成分的总和将接近零。使用乘法方法,季节性成分以相对项(百分比)表示,通过除以季节性成分对序列进行季节性调整。每年内,季节性成分总计约为m。
那么Holt-Winters 加法模型为:
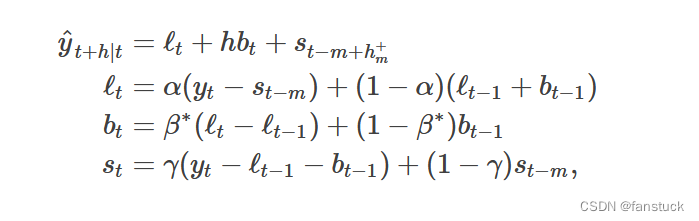
其中k是(h−1) /m的整数部分,这确保用于预测的季节性指数的估计来自样本的最后一年。水平方程显示了经季节性调整的观测值()之间的加权平均值,以及非季节性预测(
)对于时间t,趋势方程与Holt的线性方法相同。季节方程显示当前季节指数(
)之间的加权平均值 ,以及去年同一季节(即m个时间段之前)的季节性指数。
季节性分量的方程通常表示为:
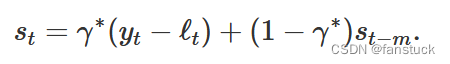
如果我们替换ℓ从上述分量形式的水平的平滑方程,我们得到
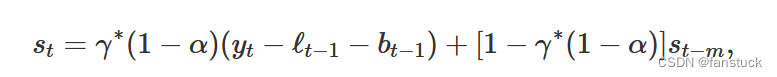
相应的,乘法模型为:
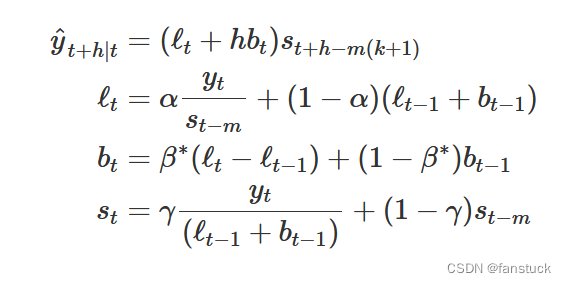
2.公式
我们大可不需要再次重新认识三次指数平滑法,三次平滑法无非就是在二次平滑法的基础之上再次平滑一次而已。那么推导公式就更加简单了:
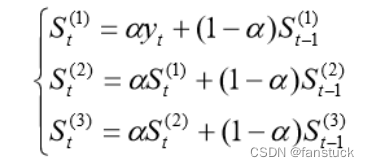
其三次平滑值的公式为:
![]()
式中为三次指数平滑值。
三次指数平滑法的预测模型为:

3.案例实现
我们的案例依旧和二次指数平滑法的案例一样,省的大家再去理解其他案例场景。
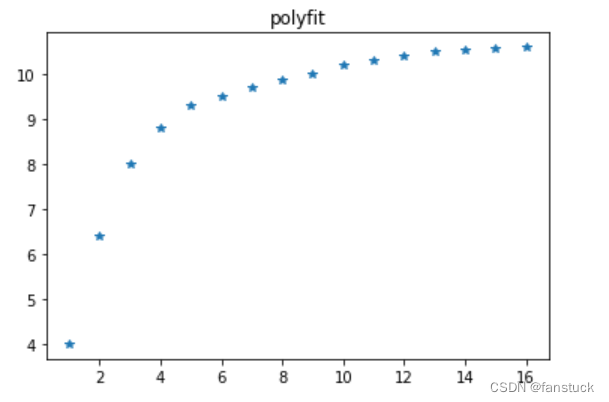
我们可以先进行绘图描点看看这些数据是否用三次指数平滑法更合适:
import matplotlib.pyplot as pltdf=pd.read_excel('try_test2.xlsx')x=df['t']y=df['发电总量y']plot1 = plt.plot(x, y, '*', label='origin data')plt.title('metric_polyfit')plt.show()
那么我们发现这个案例的数据是呈线性递增趋势,那么我们还得换个案例。这里选用上次化学反应的案例最好用。
以在某化学反应里,测得生成物浓度y(%)与时间t(min)的数据为例子:

通过实际数据序列呈非线性递增趋势,采用三次指数平滑预测方法。
确定指数平滑的初始值和权系数(平滑系数)a。设一次、二次、三次指数平滑的初始值为最早三个数据的平均值。即:
取为0.3,那么我们将
先求出来:
y_1=SES(y,3,0.3)y_2=SES(y_1,3,0.3)y_3=SES(y_2,3,0.3)之后我们使用python写出代码就好了:
#我们需要传入一次平滑预测值、二次平滑预测值和三次平滑预测值,以及t值、平滑系数a和给予的Tdef SES_triple(y_1,y_2,y_3,s,t,T): t=t-1 a=y_1[t]*3-y_2[t]*3+y_3[t] b=(s/(2*((1-s)**2)))*((6-5*s)*y_1[t]-2*(5-4*s)*y_2[t]+(4-3*s)*y_3[t]) c=((s**2)/(2*((1-s)**2)))*(y_1[t]-2*y_2[t]+y_3[t]) y=a+b*T+c*T**2 return ySES_triple(y_1,y_2,y_3,0.3,16,1) ![]()
加权系数a的选择
在指数平滑法中,预测成功的关键是 a 的选择。a 的大小规定了在新预测值中新数据和原预测值所占的比例。a 值愈大,新数据所占的比重就愈大,原预测值所占比重就愈小,反之亦然。
理论界一般认为有以下方法可供选择:
经验判断法。这种方法主要依赖于时间序列的发展趋势和预测者的经验做出判断。
1、当时间序列呈现较稳定的水平趋势时,应选较小的α值,一般可在0.05~0.20之间取值;
2、当时间序列有波动,但长期趋势变化不大时,可选稍大的α值,常在0.1~0.4之间取值;
3、当时间序列波动很大,长期趋势变化幅度较大,呈现明显且迅速的上升或下降趋势时,宜选择较大的α值,如可在0.6~0.8间选值,以使预测模型灵敏度高些,能迅速跟上数据的变化;
4、当时间序列数据是上升(或下降)的发展趋势类型,α应取较大的值,在0.6~1之间。
试算法。根据具体时间序列情况,参照经验判断法,来大致确定额定的取值范围,然后取几个α值进行试算,比较不同α值下的预测标准误差,选取预测标准误差最小的α。
在实际应用中预测者应结合对预测对象的变化规律做出定性判断且计算预测误差,并要考虑到预测灵敏度和预测精度是相互矛盾的,必须给予二者一定的考虑,采用折中的α值。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
参阅
时间序列模型 (三
指数平滑法(Exponential Smoothing,ES)_意念回复的博客-CSDN博客_指数平滑法















